이전 시간에 배운 것
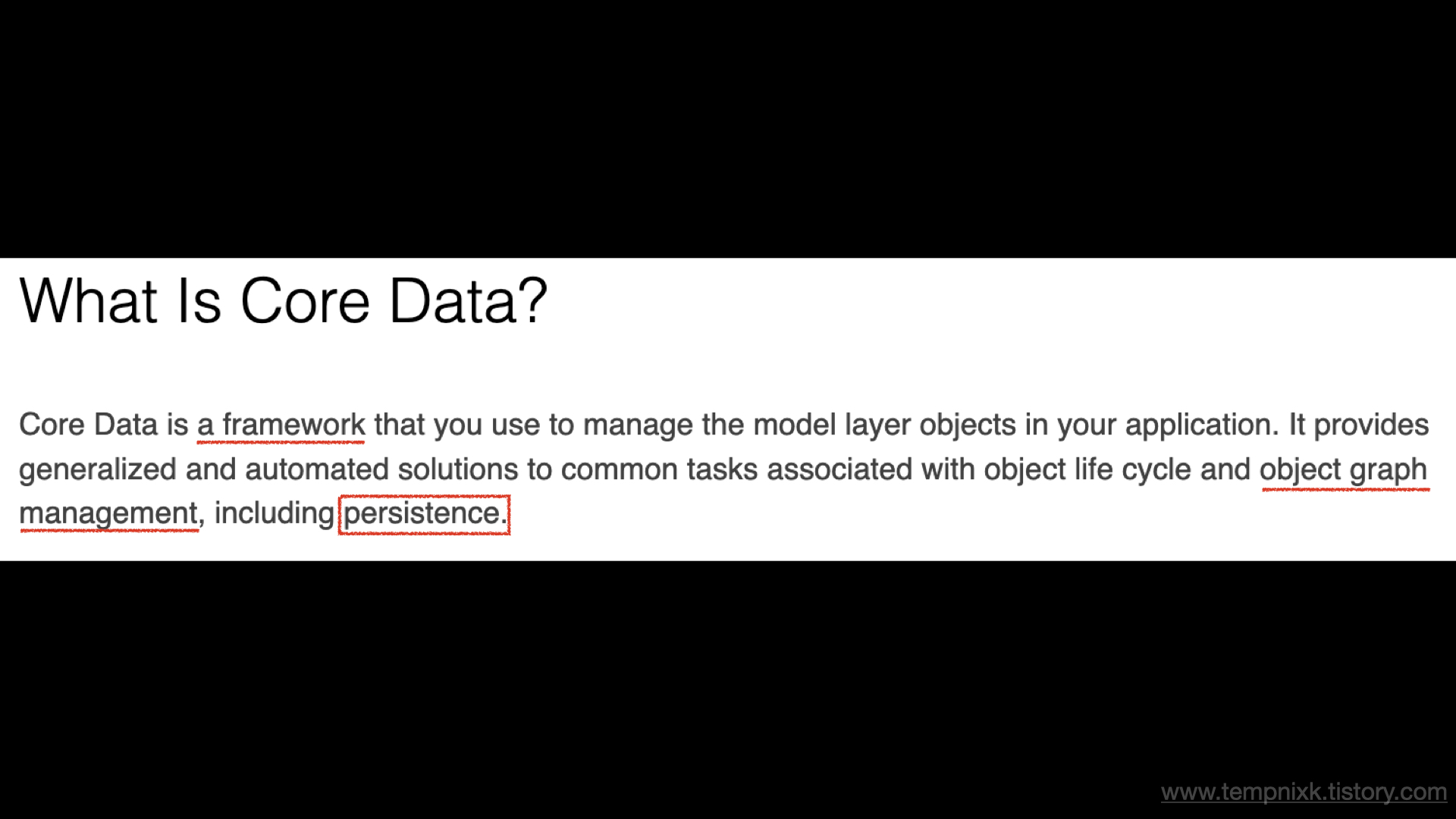
1. JPA란?
- JPA는 Java Persistence API이다.
- JPA는 ORM 기술이다.
ORM은 Object Relational Mapping의 약자로, 오브젝트를 데이터베이스에 연결하는 방법론 중 하나이다.
"ORM은 나의 하인 같은 기술"
추상적인 개념을 현실세계로 뽑아내는 개념을 모델링이라고 한다.
Team 테이블에 ID, Name, Year를 넣고 자바에서 사용을 할텐데, Input과 Output이 각각 DML(Delete, Update, Insert), Select라고한다. 자바는 테이블 데이터 타입을 가지지 않는다. 따라서 클래스를 통해서 데이터베이스의 테이블을 모델링해야한다.
class Team{
int id;
String name;
String year;
}DB 세상에 있는 데이터를 자바 세상에 모델링한다.
그런데 ORM은 Class를 먼저 만들고 DB를 자동생성할 수 있는 기술이다. JPA가 가지고 있는 인터페이스 덕분에 자바 클래스를 짜면 테이블을 만들 수 있다.
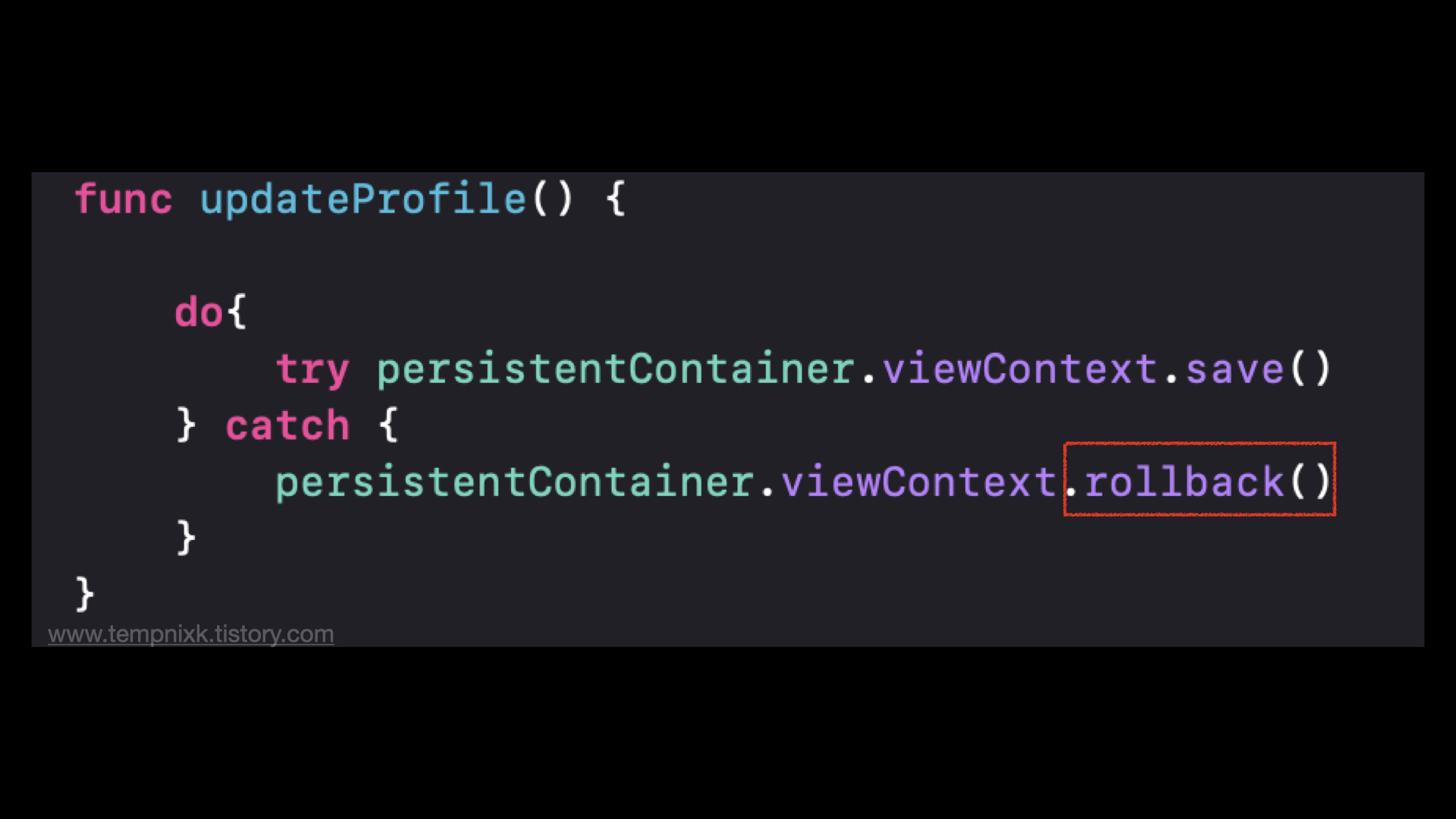
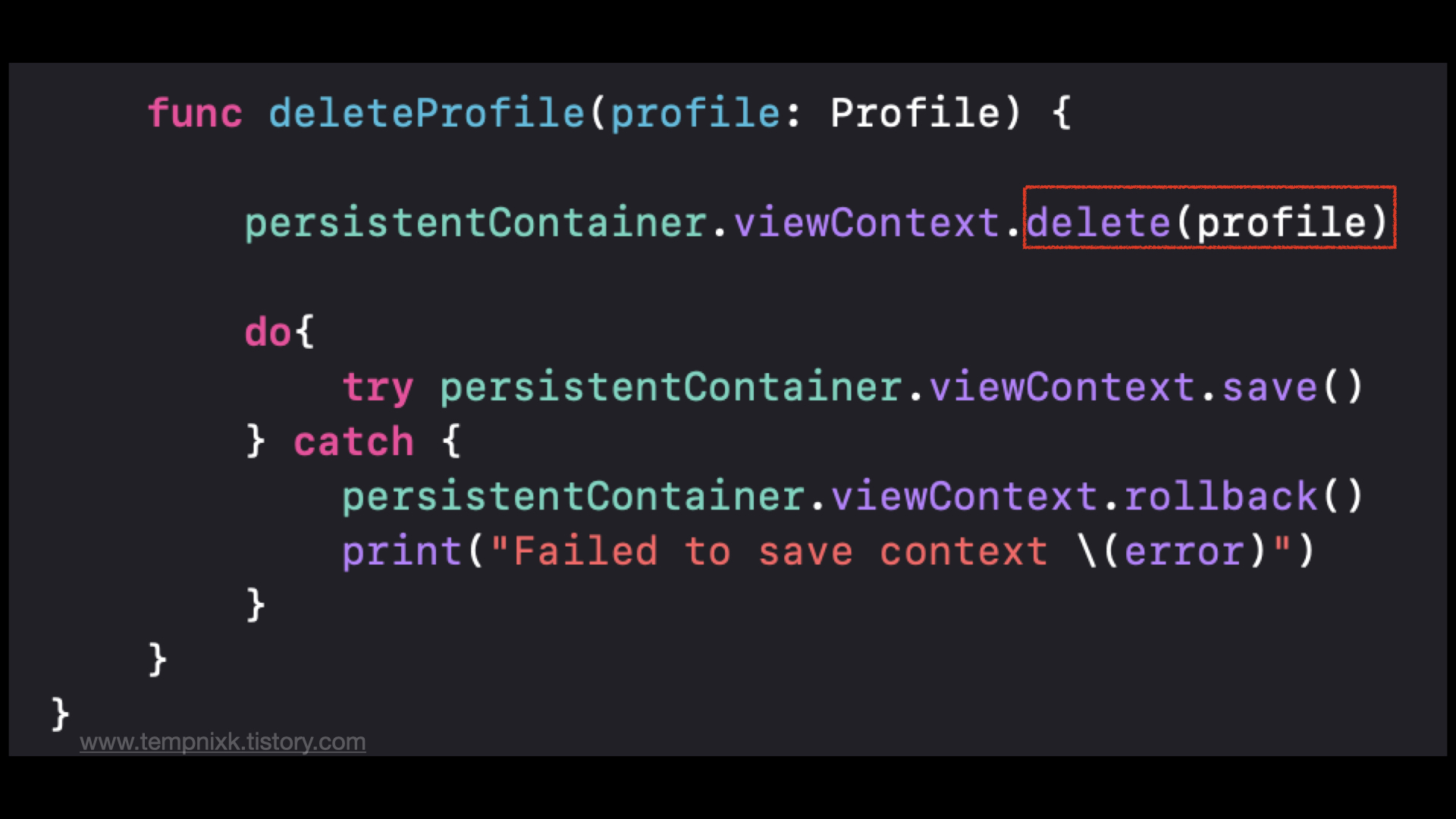
- JPA는 반복적인 CRUD 작업을 생략하게 해준다.
Select 1건
Select All 전체
Delete 1건
Update 1건
Insert 1건
자바에서 DB로 연결하기위해서 신원을 확인하고 DB가 세션을 오픈하면 커넥션 시킬 수 있다. 이때 자바가 쿼리를 전송한다. DB는 해당 쿼리를 통해, 어떤 작업을 통해 데이터를 만들어내고, 자바에 응답한다. 응답시 DB 타입값과 자바 타입값이 다르기 때문에 자바 Object로 바꿔야한다. 이때 자바 Object로 바꾸는 작업은 단순한 반복노동이기에 JPA를 사용해서 전송된 쿼리에 대한 응답이 있을때 이 데이터를 받고 자바 오브젝트로 바꾸고 연결된 세션을 끊고, 연결된 커넥션을 끊고하는 이러한 모든 일련의 과정들을 함수 하나로 제공해준다. 기본적인 CRUD를 단순하게 처리하도록 도와준다. 이런 단순한 CRUD를 도와주는 것도 ORM이 해준다.
다음 시간에 배울 내용
- JPA는 영속성 컨텍스트를 가지고 있다.
- JPA는 DB와 OOP의 불일치성을 해결하기 위한 방법론을 제공한다. (DB는 객체저장 불가능)
- JPA는 OOP의 관점에서 모델링을 할 수 있게 해준다. (상속, 콤포지션, 연관관계)
- 방언 처리가 용이하여 Migration하기 좋음. 유지보수에도 좋음
- JPA는 쉽지만 어렵다.
이 블로그 포스팅은 인프런 최주호님의 스프링부트 개념정리(이론) 강의에 대한 정리 포스팅입니다.
다음은 강사님의 강의 링크입니다. 무료 강의라서 가입만 하면 볼 수 있습니다. (강의 링크)
'웹 개발 > Spring Boot' 카테고리의 다른 글
| OOP 관점에서 모델링이란 무엇일까요? (0) | 2023.08.01 |
|---|---|
| 영속성 컨텍스트란 무엇인가요? (0) | 2023.07.31 |
| JPA란 무엇인가요? (0) | 2023.07.30 |
| 메시지 컨버터가 무엇인가요? (0) | 2023.07.30 |
| 필터란 무엇인가요? (0) | 2023.07.29 |